●표준편차(標準偏差) 란?
사전적 의미를 살펴보면,
“자료의 분산(分散, 분리되어 흩어진) 정도를 나타내는 수치. 분산의 양의 제곱근으로,
표준편차가 작은 것은, 평균값 주위의 분산의 정도가 작은 것을 나타낸다.”
라고 되어있다.
그래서, 위의 어려운 말을 풀어서 말해보면, 자료가 얼마나 흩어져 있는지를 말하는 수치라는
것이다. 그런데 얼마나 흩어져 있는지를 말하려면 기준이 있어야 되는데(범위나 중심), 표준
편차에서 말하는 기준은 평균값(중심)을 말한다. 평균값을 중심으로 어떻게 흩어져 있는지를
살필 수 있는 값이라는 말이다. 아래 그래프를 보면 조금 더 이해가 쉬우리라 생각된다.
이 그래프에서 표시되는 자료의 평균값은 60으로 좌우의 그래프에서 동일하다.
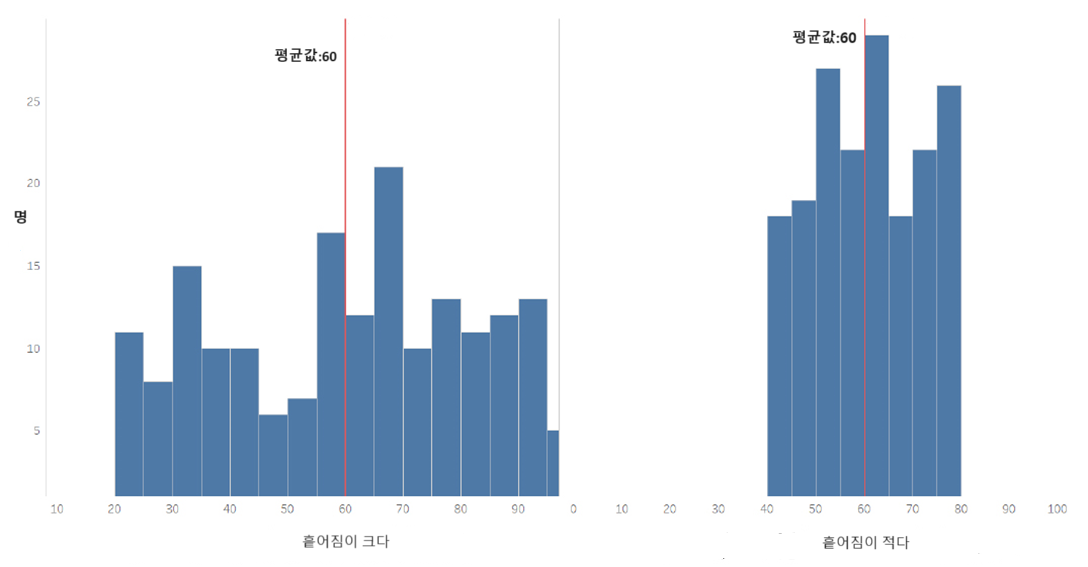
위의 자료를 한 중학교의 시험성적이라고 가정하면 왼쪽의 A반은 학생들의 점수차가 오른쪽
B반보다 크다고 말할 수 있다.
여기까지 듣고 표준편차가 잘 이해되는 사람은 공부를 꽤 했던가 아니면 천재다. 다음 글은 안
봐도 된다. 그런데 "뭐 어쩌라고"라는 생각이 드는 사람은 조금만 참고 진도 좀 나가자. 앞으로
더 요상한 용어들이 무궁무진 등장한다. 여기서 포기하면 AI쪽은 손 놓아야 한다.
그럼 첫 단계로 편차(偏差)
1. 편차(偏差)
편차란 평균값과의 차이이다. 어떤 자료가 평균값 보다 얼마나 큰지 혹은 작은지를 말하는 용어
이다.

평균값이 60인 테스트 자료에서 B는 50점, E는 80점을 받았다라고 가정 하면,
B = 50점 – 60점 = -10점(평균보다 10점이 적다 = 편차가 -10)
E = 80점 – 60점 = +20점(평균보다 20점이 많다 = 편차가 +20 )
편차라는 말이 이해 되는가? 그럼 표준편차는 간단하다. 말 그대로 표준적인(평균적인) 편차값
이라는 말이다.
좀 헷갈리는 말이 등장했다. 표준적인 편차(?)
다시한번 편차의 의미를 생각해 보자. 평균값과의 차이이다. 근데 평균값과의 차이를 굳이 편차
라는 어려운 말로 표현해야 될까? 그냥 (대상 값 – 평균)이라고 하면 쉽지 않나? 그런데, 이렇게
하면 몇가지 치명적인 모순이 발생하게 된다. 첫번째는 음의 숫자가 생기게 된다는 것이다. 떨어
져 있는 정도를 표현하는데 음의 숫자가 포함되어 버리면 통계처리를 하는데 장애가 될 수 있다.
두번째는 편차의 평균값을 계산할 수 없게 된다는 것이다. (대상 값 – 평균)의 정의를 가져오게 되
면 같은 값(부호가 반대인)이 2개씩 생겨나게 되는데(평균값을 중심으로), 이때 부호가 반대인 두
수를 합하면 0이 되어 버린다. 그래서 이 정의를 사용하여 계산한 표준편차는 항상 값이 0이 된다.
이런 단점을 극복하고 표준편차라는 방법을 사용하기 위해 계산방법을 조금 변형시켜 놓았다.
방법은 간단하다. 쉽게 음의 숫자가 되지 않도록 제곱해서 평방근(루트)을 씌워 버린 것이다.
모든 숫자는 제곱해서 루트를 씌우면 양의 수가 된다. -2 ⇒ 4 ⇒ 2, -9 ⇒ 81 ⇒ 9 이런 식이다.
이 방식이라면 (대상 값 – 평균: 편차)을 적용해서 평균을 내도 0이 되지 않는다.
즉, 편차의 평균값, 표준(평균값)이 되는 편차라는 의미이다.
2. 표준편차를 사용하면 전체 데이터중에서 특정 데이터의 대략적인 위치를 파악할 수 있다.
표준편차를 알면 특정 데이터가 전체 데이터 중에서 어디에 위치하는지 파악할 수 있게 된다. 그러
니까 다음과 같은 경우가 발생한다는 말이다.
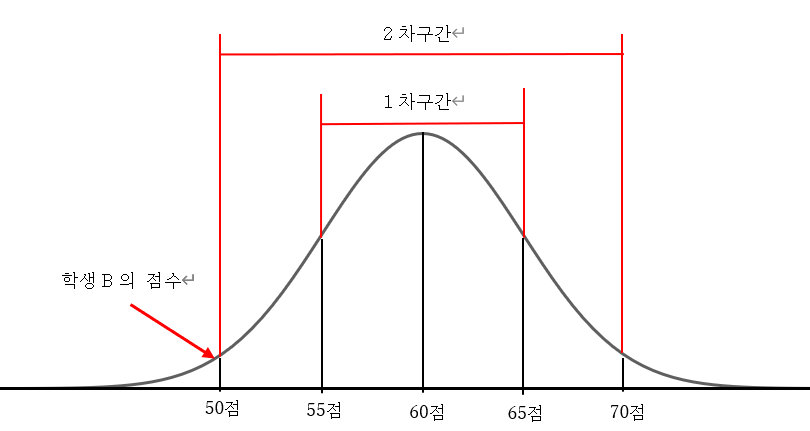
어떤 학생 B가 기말시험에서 50점을 얻었다고 가정하자. 선생님이 알려 준 학급 평균점수가 60점
이라니 10점 차이밖에 나지 않는다고 이번에는 꽤 노력했다고(?) 행복해하고 있었다. 그런데, 정말
행복해 해도 괜찮은지 표준편차로 알아보자. 선생님이 발표한 기말고사의 표준편차는 5였다. 평균
점과 표준편차를 합쳐서 생각하면
평균점 = 60점, 표준편차 = 5, 1차구간 : 55점 ~ 65점, 2차구간 : 50점 ~ 70점
많은 학생들이 55(60 – 5)점 과 65(60 +5)점 사이에 위치해 있게 되므로 이번에도 그리 행복해 할
일은 아닌듯 싶다.
이와같이 표준편차를 이해하게 되면 대상 데이터가 전체 데이터 중에서 어떤 성격의 데이터인지
이해 할 수 있게 된다.
1) 흔치않은 특이한 데이터 인가?
2) 흔히 나타나는 데이터 인가?
이렇게 데이터의 특성을 알아내는데 도움이 되는게, 또하나 있는데 68%룰과 95%룰이 그것이다.
3 표준편차의 68%룰 과 95%룰
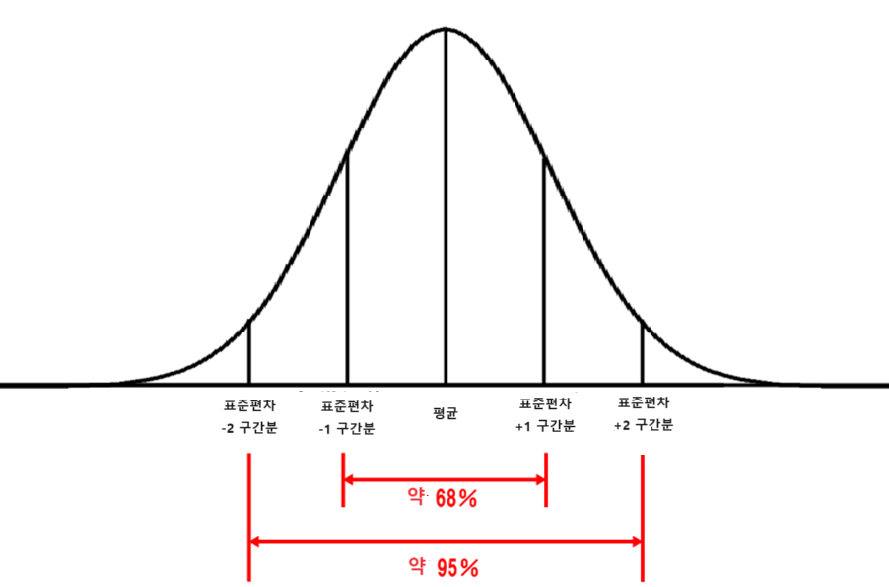
표준 편차에는 다음과 같은 룰 있다.
평균값으로부터 ±표준편차 1차구간 만큼에 포함되는 데이터는 전체의 약 68%가 된다.
평균값으로부터 ±표준편차 2차구간 만큼에 포함되는 데이터는 전체의 약 95%가 된다.
※조건 : 위의 룰은 데이터 분포가 정기분포일 경우만 해당된다.
예를들어, 데이터 수가 100개 이고 그 평균값이 50, 표준편차가 5라고 하면, 평균값±표준편차 한
개분만큼 떨어졌다는 말은 50±5라는 의미니까, 45~55의 범위내에 68%의 데이터, 즉
100x68% = 약68개
의 데이터가 분포하게 된다는 의미이다.
이와같이 어떤 데이터의 전체데이터에 대한 상대위치를 알면, 평균값뿐만 아니라 그 데이터가
평균값에서 표준편차 몇개분 떨어져 있는가 라는 걸 기준으로 잡을 수 있게 되는데, 이것이 상당
히 유용하다.
☆「표준편차 몇개분인가?」를 계산하는 방법
각 데이터가 표준편차 몇개분인지 알기 위해서는
(데이터 평균값) ÷ 표준편차
의 식으로 계산할 수 있다. 예를들어, 평균값 50점, 표준편차 5점인 경우에 65점을 얻었다고 가정
하면, 이 65점이 표준편차 몇개분인가를 계산해보면
(65점 – 50점) ÷ 5 = 15점 ÷ 5점 = 3
이 되어 표준편차 3개분의 데이터가 된다.
'AI는 정답일까? > 통계에 관한 지식' 카테고리의 다른 글
| 표준편차에 대해서 #2 (0) | 2024.08.19 |
|---|
